
Carnet Tech en Vrac
INDEX
- PG_HBA.CONF
- VUES POSTGRES
- DATAMESH
- OLAP vs OLTP
- ELT vs ETL
- TYPE DE TABLES
- DATA LINEAGE
- DATA GOUVERNANCE
AUTRE
- VIRTUALISATION
- WSL
- DU -SCH vs LS -LTR
- MONTEE DE VERSION DE SERVEURS
DOCKER
- OVERLAY2
- .WSLCONFIG
- DOCKER0
- user: root
- init.sql:ro
- DJANGO
- VS CODE (astuces)
- load_dotenv
DATA
OLAP (Online Analytical Processing) et OLTP (Online Transaction Processing) sont deux approches différentes pour gérer et utiliser les données en fonction des besoins :
- OLTP est utilisé pour les opérations quotidiennes rapides et précises. Par exemple un site marchand ou une messagerie instantanée. Il faut être capable de gérer de nombreuses transactions simples rapidement. Il y a donc un besoin élevé de performance et de fiabilité. (Exemples de Technos : MySQL, PostgreSQL, Oracle, SQL Server).
- OLAP est utilisé pour l’analyse et la prise de décision basée sur les données. Typiquement du Dashboarding, de la Dataviz / Data Analyse. Il a donc un besoin de bases de données optimisées pour des requêtes complexes sur de grandes quantités de données. C’est ici qu’on retrouvera essentiellement le modèle de raffinerie de données. (Exemples de technos : Redshift, BigQuery, Snowflake.)
ETL (Extract, Transform, Load) et ELT (Extract, Load, Transform) sont deux processus utilisés pour intégrer et préparer des données provenant de différentes sources pour l’analyse ou le stockage dans un entrepôt de données (data warehouse).
Dans un ETL les données sont transformées en dehors du système de destination. Cela peut inclure des opérations comme le nettoyage des données, l’agrégation, la conversion des formats, et l’application de règles de gestion. Ce n’est qu’ une fois transformées, les données sont chargées dans le système de destination (datawarehouse par exemple).
Exemples : Apache Nifi, Talend, Power Query
En revanche, dans un ELT, les données brutes sont directement chargées dans le système de destination. Les transformations sont effectuées après le chargement des données dans le système de destination. Les données sont ensuite transformées en utilisant la puissance de calcul de l’entrepôt de données ou du data lake.
Exemples : Google BigQuery, Amazon Redshift, Snowflake, Azure Synapse Analytics, et Databricks
Donc en gros, pour du big data on préférera l’ELT à l’ETL car il exploite la puissance de calcul des entrepôts de données modernes et des data lakes.
Pour aller plus loin : Article de IBM
CYBERSECURITE
EICAR
EICAR (European Institute for Computer Antivirus Research) est une organisation qui a, entre autres, créé un fichier de test standardisé pour vérifier le bon fonctionnement des logiciels antivirus. C’est est un fichier texte inoffensif qui contient une chaîne de caractères spécifique. Lorsque ce fichier est scanné par un antivirus, il doit être détecté comme un virus, même si ce n’en est pas un. L’objectif est de permettre aux utilisateurs de tester leurs logiciels antivirus pour s’assurer qu’ils fonctionnent correctement.
Voici ce qu’il contient :
X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*
Pour l’utiliser il faut enregistrer cette chaîne de caractères dans un fichier texte sous le nom eicar.com ou tout autre nom de fichier avec l’extension .com, .exe, .bat, .ps1 ou autres…
Puis lancer le scan avec l’antivirus.
Sitemap.xml et Robot.txt
sitemap.xml est un fichier au format XML qui contient une liste de toutes les pages d’un site web, offrant ainsi aux moteurs de recherche un moyen de découvrir facilement et efficacement les différentes pages à indexer du site. Il permet de guider les moteurs de recherche, comme Google, à explorer (ou « crawler ») un site pour indexer son contenu.robots.txt empêche l’exploration des pages par les moteurs de recherche, mais n’empêche pas qu’elles figurent dans le sitemap.xml.Voici le mien.
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-content/uploads/private/
Allow: /wp-content/uploads/public/
Disallow: /private-page/
Sitemap: https://www.exemple.com/sitemap.xml
User-agent: * : Cela signifie que les règles suivantes s’appliquent à tous les moteurs de recherche. Pour définir des règles spécifiques pour un moteur de recherche particulier (par exemple, Google), remplacer * par le nom du robot, comme Googlebot.
Disallow: /wp-admin/ : Cela empêche les moteurs de recherche d’explorer toutes les pages du répertoire /wp-admin/, qui est le répertoire d’administration de WordPress.
[…]
Disallow: /secret-folder/ : Empêche les moteurs de recherche d’explorer le dossier /secret-folder/ et son contenu.
ATTENTION RAPPEL : La directive Disallow dans robots.txt indique aux moteurs de recherche de ne pas explorer ou crawler les pages ou répertoires spécifiés, mais elle n’empêche pas ces pages de figurer dans le sitemap XML
Pour en savoir plus : le site de la marmite – robots.txt et le site de la marmite – sitemap.xml !
DOCKER
.WSLCONFIG
vmmem est utilisé par Docker Desktop sur Windows lorsqu’il fonctionne avec WSL 2 (Windows Subsystem for Linux). WSL 2 utilise une machine virtuelle légère pour exécuter les distributions Linux, et cette machine virtuelle consomme de la mémoire qui est représentée par le processus vmmem.Get-Process -Name vmmem | Format-Table Id, Name, @{Name="WorkingSet(MB)";Expression={$_.WorkingSet64/1MB -as [int]}} -AutoSize
vmmem (Virtual Machine Memory) dans Windows, il faut configurer les paramètres de WSL 2. Pour cela :- Se placer dans C:\Users\VotreUserName\
- créer un fichier nommer .wslconfig contenant ceci :
[wsl2]
memory=4GBOn peut spécifier cette valeur en Go (GB), Mo (MB), ou Ko (KB) selon les besoins.
Puis on redémarre wsl avec :
# extinction
wsl --shutdown
# re-démarrage
wsl -d DistributionToRebootvmmem a 4GB de RAM.
OVERLAY2
Le dossier overlay2 se trouve généralement dans le répertoire /var/lib/docker/ (le répertoire de données par défaut de Docker). Il contient plusieurs éléments liés à la gestion des conteneurs et des images Docker.
Ce dossier peut grandir considérablement si tu utilises beaucoup d’images et de conteneurs Docker. Chaque fois qu’un nouveau conteneur est lancé ou qu’une image est téléchargée, de nouvelles couches peuvent être créées et stockées dans ce dossier. Si tu as beaucoup de conteneurs qui ne sont pas supprimés, ou si des images sont fréquemment téléchargées, le dossier peut rapidement atteindre une taille importante.
Pour le nettoyer :
#Supprimer les conteneurs inutilisés :
docker container prune
#Supprimer les images non utilisées :
docker image prune
#Pour supprimer les volumes non utilisés :
docker volume prune
#Supprimer tous les conteneurs, images, volumes et réseaux inutilisés :
docker system prune
#Nettoyer les images et les conteneurs non référencés :
docker image prune -a
docker container prune -a
Utiliser du -sch pour voir la différence de poids après nettoyage.
RESEAU
0.0.0.0 vs 127.0.0.1 vs Localhost
127.0.0.1: C’est une adresse IP spéciale qui fait référence à l’ordinateur lui-même. Les données restent dans le système. C’est une adresse de loopback.localhost: C’est un nom de domaine qui est presque toujours associé à l’adresse127.0.0.1. Voir le fichier host : C:\Windows\System32\Drivers\etc\hosts ou /etc/hosts (linux)
0.0.0.0 signifie « toutes les adresses IP » ou « n’importe quelle adresse IP ». Elle est souvent utilisée pour dire qu’un serveur doit écouter sur toutes les interfaces réseau disponibles. C’est à utiliser dans des config !
Exemples :
- Lorsqu’un serveur (comme un serveur web ou une application) est configuré pour écouter sur l’adresse
0.0.0.0, cela signifie qu’il accepte les connexions sur toutes les interfaces réseau de la machine. Autrement dit, il peut recevoir des requêtes venant de n’importe quelle adresse IP assignée à la machine, y comprislocalhost, mais aussi d’autres adresses IP locales ou externes. Si notre machine a pour IP locale192.168.1.10on pourra ccéder au serveur web vialocalhost,127.0.0.1, et192.168.1.10.
DEV
load_env()
from dotenv import load_dotenv
load_dotenv()
# en amont pip install python-dotenv
# Accéder aux variables d'environnement
api_key = os.getenv('API_KEY')
db_password = os.getenv('DB_PASSWORD')
debug_mode = os.getenv('DEBUG')
.env dans un environnement Python. Cela permet de séparer la configuration de l’application (comme les clés API, les mots de passe et autres informations sensibles) du code source de l’application. mon_projet/
│
├── .env
├── main.py
└── autres_fichiers.py
API_KEY=12345abcdef
DB_PASSWORD=supersecretpassword
DEBUG=Trueload_dotenv() cherche le fichier .env dans le répertoire où le script Python est exécuté. Si le fichier .env est placé dans un autre répertoire, on peut spécifier son chemin relatif ou absolu comme argument pour load_dotenv().load_dotenv(dotenv_path='config/.env')
- Ajouter le fichier
.envà.gitignorepour éviter qu’il ne soit inclus dans les dépôts Git. - Limiter l’accès au fichier
.enven modifiant ses permissions, avec unchmod 600 .envpar exemple. - S’assurer que le répertoire racine ou le fichier
.envn’est pas accessible par le serveur web en configurant le serveur (Apache, Nginx, etc.) pour bloquer l’accès direct aux fichiers sensibles. - Une bonne pratique consiste à stocker des variables d’environnement directement au niveau du système d’exploitation par exemple dans le fichier
/etc/environmentou dans un script bash de démarrage.export DB_PASSWORD="supersecretpassword" - Utiliser un gestionnaire de secrets pour stocker et gérer les informations sensibles comme Vault de HashiCorp, AWS Secrets Manager, ou Azure Key Vault.
- Et autres solution de cryptage, WAF etc
Remarque : Docker Compose prend automatiquement en charge la lecture du fichier .env et injecte ces variables dans les conteneurs lorsqu’ils sont lancés. Plus besoin de load_env().
version: '3'
services:
db:
image: mysql:5.7
environment:
- MYSQL_ROOT_PASSWORD=${DB_PASSWORD}
- MYSQL_USER=${DB_USER}
- MYSQL_PASSWORD=${DB_PASSWORD}
- MYSQL_DATABASE=mydatabase
ports:
- "3306:3306"
networks:
- mynetwork
networks:
mynetwork:
driver: bridge
DB_USER=myuser
DB_PASSWORD=mysecretpassword
DB_HOST=localhost
AUTRES
DU -SCH vs LS - LTR
du -sch et ls -ltr sont toutes deux utilisées pour obtenir des informations sur les fichiers et répertoires dans un système Unix ou Linux, mais elles servent des objectifs différents et présentent des informations de manière distincte.du -sch /chemin/vers/répertoire
# du : Signifie "disk usage" (utilisation du disque). Cette commande affiche l'espace disque utilisé par les fichiers et répertoires.
# -s : Résumé. Affiche uniquement le total pour chaque argument.
# -c : Total. Affiche un total cumulé pour tous les arguments fournis.
# -h : Human-readable. Affiche les tailles dans un format lisible par l'homme (Ko, Mo, Go).
# remarque : pour avoir que les fichier les plus
# volumineux (gigaoctets)
du -sch * | grep Gls -ltr /chemin/vers/répertoire
# ls : Liste les fichiers et répertoires.
# -l : Format long. Affiche des informations détaillées sur les fichiers (permissions, nombre de liens, propriétaire, groupe, taille, date de modification, nom).
# -t : Trie par date de modification, du plus récent au plus ancien.
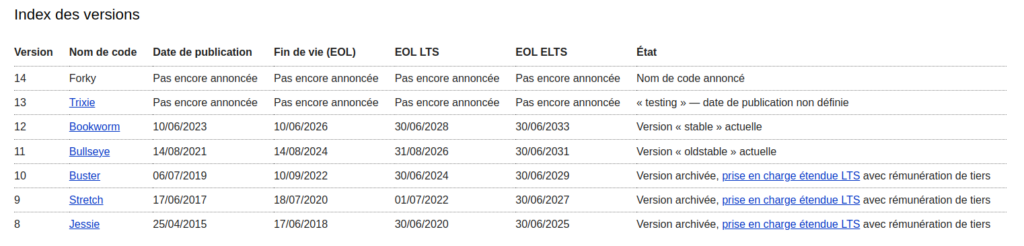
# -r : Inverse l'ordre de tri. Avec -t, cela affiche du plus ancien au plus récent.Montée de versions de serveurs Linux
Voir sa version
cat /etc/os-release
# ou
lsb_release -a
cat /etc/apt/sources.list
# Peut aussi fournir des informations intéressantesMontée de version mineure
# Pour des mises à jour de sécurité régulières
sudo apt update
sudo apt upgrade
# Pour une mise à jour complète du système sans installer de nouvelles versions majeures de paquets :
sudo apt full-upgrade
Montée de version majeure
- une montée de version sur Red Hat (ou CentOS) peut être réalisée différemment, avec des commandes spécifiques, comme
dnfouyumpour les versions plus anciennes. De plus RHEL (Red Hat Entrprise Linux) est une distro payante donc la documentation n’est pas aussi facilement trouvable. - Dans le cadre d’Ubuntu, une convention a été mise en place pour la numérotation des versions de la distribution. Les numéros de version d’Ubuntu sont composés de deux chiffres représentant respectivement le mois et l’année de la sortie. Par exemple, pour Ubuntu 20.04, le
20représente l’année (2020) et le04représente le mois (avril). Seules les versions paires sont LTS.
