
Analyse de la qualité des données : une Intégration ETL Fiable et Efficace
L’analyse de la qualité des données est une étape cruciale dans tout processus de gestion des données. Elle permet de garantir que les données utilisées pour des analyses, des rapports ou des prises de décision sont fiables, précises, et cohérentes. Cette méthodologie s’applique dans divers contextes, notamment avant ou après le processus de raffinage des données, et elle est essentielle pour s’assurer que les données sont prêtes à être exploitées, ou pour définir quels traitements celles-ci devront subir dans l’ETL.
1 - Contexte
L’analyse de la qualité des données est généralement effectuée en amont d’un projet de gestion de données, notamment avant le raffinage des données. Cependant, elle peut également être utile après un premier processus de raffinage pour vérifier que les transformations appliquées n’ont pas introduit de nouvelles erreurs ou incohérences.
Rappel :
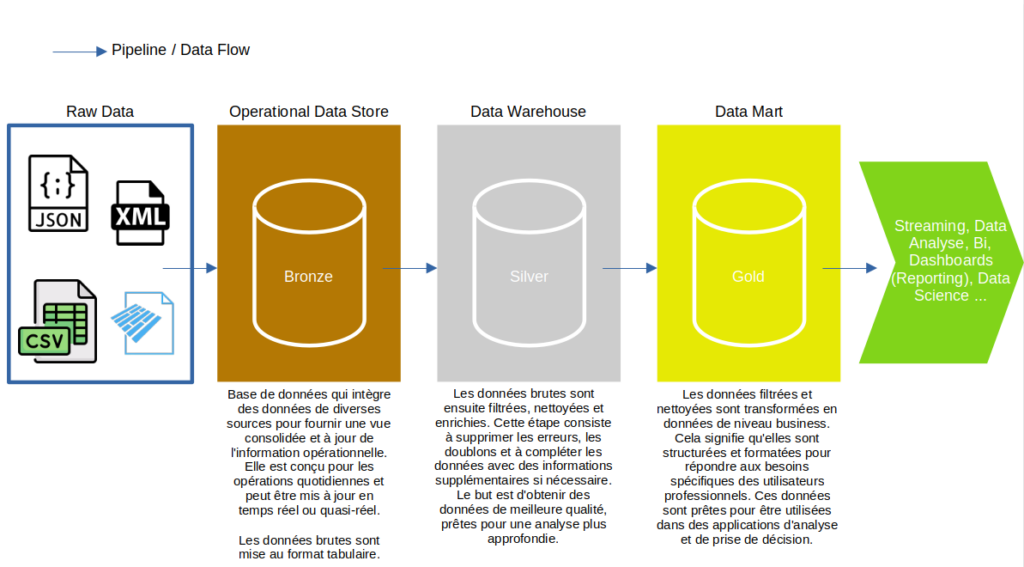
Dans notre exemple nous nous placerons avant le raffinage des données. Cette analyse permet de détecter les problèmes de qualité dès le départ, ce qui facilite la mise en place de stratégies de nettoyage et d’amélioration de la qualité des données avant leur exploitation. Cela est particulièrement utile lorsqu’il s’agit d’intégrer des données provenant de multiples sources, qui peuvent avoir des formats et des niveaux de qualité variés.
2 - Prérequis
- Identifier les sources (csv, json, API …) et leurs contraintes (accès, volume, formats…)
- Déterminer les critères de qualité :
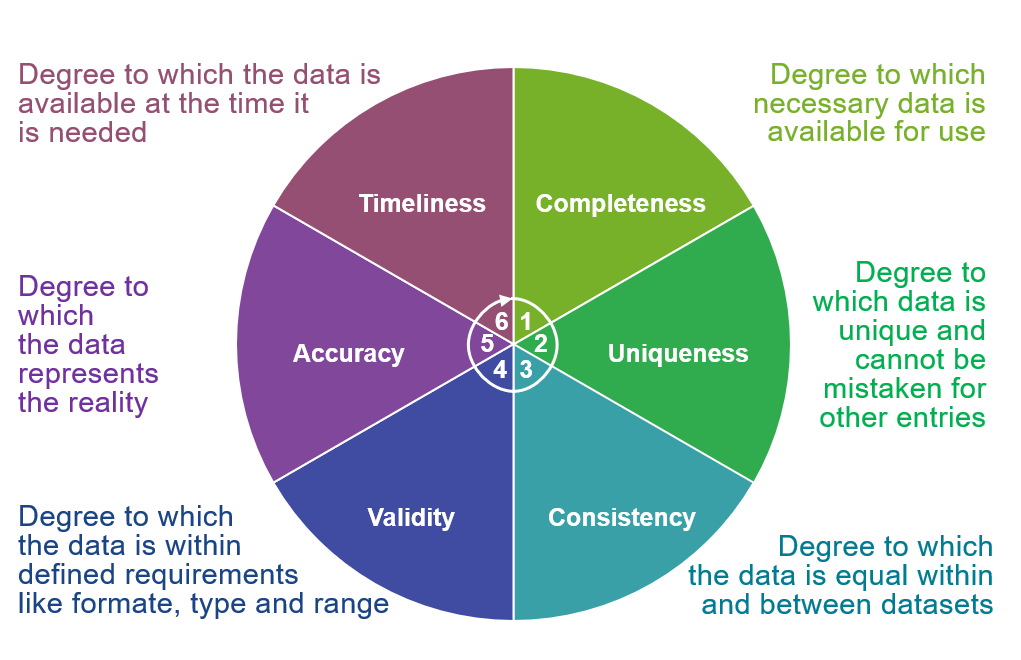
L’image ci-dessus, emprunté à ce site (Lean-Data), illustre les différents dimensions de qualité des données, à considérer tout au long du cycle de vie des données :
Completeness (Complétude) : Le degré auquel toutes les données nécessaires sont disponibles pour une utilisation.
Uniqueness (Unicité) : Le degré auquel les données sont uniques et ne peuvent pas être confondues avec d’autres entrées.
Consistency (Cohérence) : La mesure dans laquelle les données sont égales au sein d’un même jeu de données et entre différents jeux de données.
Validity (Validité) : Le degré auquel les données respectent les exigences définies, telles que le format, le type, et les plages de valeurs.
Accuracy (Exactitude) : Le degré auquel les données représentent fidèlement la réalité.
- Timeliness (Temporalité) : La mesure dans laquelle les données sont disponibles au moment où elles sont nécessaires.
Ainsi on obtient un mapping global des données en entrée de notre ETL et les dimensions à privilégier. Une fois que ces données en entrée sont appréhendées nous sommes prêt pour attaquer la préparation au nettoyage.
2 - Définition des Exigences (Nettoyage de la donnée)
Ici on s’attaque surtout à l’aspect validité des données. Il faut donc définir les critères et les normes à appliquer aux données:
- Traitement des champs vides
- Typage
- Formatage (Regex)
- Traitement des doublons, en s’assurant que les doublons ne créent pas d’incohérences (problématiques de clés primaires et clés étrangères)
Remarque : Le Data Architect doit avoir fournit les spécification fonctionnelles / diagramme UML cibles de la BDD pour les différents schémas ODS (Operational Data Store), DWH (DataWarehouse), DMT (DataMart).
3 - Collecte et exploration des données
Ici on requête (SQL, API …) un échantillon dont la taille significative est définie en amont dans chacune des sources du projet. Cela permet de définir quelles transformations devront être appliquées à chacune des sources de données en fonction des critères et exigences définis en amont.
Une évaluation de la qualité / intégrité des données peut-être menée sur ces échantillons :
- Etude de cohérence : c’est à dire la cohérence entre les champs des doublons
- Etude de la complétude des données : Les données doivent être complètes au niveau des champs obligatoires, sans valeurs manquantes là où des informations sont attendues.
- Unicité : S’assurer que les valeurs censées être uniques le sont effectivement, soit pas de doublons sur les champs contraints par des clés primaires ou clés étrangères.
- Consistance : Vérifier que les données sont cohérentes entre elles, notamment lorsque des champs sont censés être corrélés.
- Distribution : Vérifier la présence de valeurs aberrantes à écarter
- Analyse statistiques sur :
- le champs vides
- Les champs NULL
- Les doublons
- …
- …
4 - Analyse et préconisations
Ici pour faire les choses proprement il s’agit d’un étape de reporting avec un dashbord et de la belle dataviz afin de présenter les résultats de l’analyse de manière claire (et si possible interactive).

Ainsi, à la suite de la visualisation des indicateurs clés de qualité pour faciliter la prise de décision, on peut enfin faire une proposition / préconisation de stratégie de nettoyage des données afin d’en améliorer la qualité, éventuellement au travers de spécification techniques détaillées. Ici basiquement l’utilisation d’un ETL pour créer des pipelines de nettoyage de données.


Conclusion
Ici nous avons vu la méthodologie d’analyse de la qualité des sources de données en vue de mettre en place une solution d’ETL.
La méthodologie d’analyse de la qualité des données est un processus essentiel pour garantir la fiabilité des données avant toute exploitation. Elle s’intègre aussi bien avant qu’après le raffinage des données, permettant de détecter et de corriger les problèmes potentiels tout au long du cycle de vie des données. Après le raffinage des données une nouvelle analyse de qualité peut donc être effectuée pour valider l’efficacité des processus de nettoyage et de transformation.


