
Supervision avec Prometheus et Grafana
Cet article est un complément à l’article dockerisation d’un cluster spark et a pour but d’ajouter une solution de monitoring des conteneurs en utilisant la synergie Prometheus x Grafana.
1 - Structure du projet
Dans notre projet il va nous falloir ajouter quelques dossiers ( etc et dans data) tels que :
project-root/
│
├── docker-compose.yml
│
├── data
│ └── flights.csv
├── docker-compose.yml
├── etc
│ ├── grafana
│ └── prometheus
│ └── prometheus.yml
│
├── data/
│ ├── grafana
│ ├── prometheus
│ ├── example_data.csv
│ └── ...
│
├── ScriptsPy/
│ ├── example_script.py
│ └── ...
│
├── models/
├── example_model.pkl
└── ...
Le fichier prometheus.yml doit contenir les lignes suivantes :
global:
scrape_interval: 5s # Intervalle de récupération des métriques (scrape) par Prometheus. Ici, il est défini à 5 secondes.
evaluation_interval: 5s # Intervalle d'évaluation des règles. Prometheus évalue les règles toutes les 5 secondes.
# scrape_timeout est défini par défaut à 10 secondes (scrape_timeout par défaut).
# Attache ces étiquettes à toute série temporelle ou alerte lors de la communication avec
# des systèmes externes (fédération, stockage à distance, Alertmanager).
external_labels:
monitor: 'codelab-monitor' # Étiquette externe "monitor" définie comme 'codelab-monitor'.
# Charge les règles une fois et les évalue périodiquement selon 'evaluation_interval' global.
rule_files:
# - "first.rules" # Fichier de règles à charger (commenté).
# - "second.rules" # Autre fichier de règles à charger (commenté).
# Une configuration de récupération (scrape) contenant exactement un point de terminaison à interroger :
# Ici, c'est Prometheus lui-même.
scrape_configs:
- job_name: 'node' # Nom du job de scrape, ici c'est "node".
static_configs:
- targets: ['192.168.1.26:9100'] # La cible à interroger (l'adresse IP et le port où les métriques sont disponibles).
global : Cette section définit les paramètres globaux pour Prometheus, comme l’intervalle entre chaque collecte de métriques (
scrape_interval) et l’intervalle entre chaque évaluation des règles (evaluation_interval).external_labels : Ce sont des étiquettes ajoutées à chaque série temporelle et alerte avant de les envoyer à des systèmes externes. Ici, on ajoute l’étiquette
monitoravec la valeurcodelab-monitor.rule_files : Cette section permet de spécifier les fichiers de règles (fichiers
.rules) que Prometheus doit charger. Les règles permettent de générer des alertes ou de créer de nouvelles séries temporelles basées sur les séries existantes. Les deux lignes sont commentées ici, donc aucun fichier de règles n’est chargé.scrape_configs : Cette section définit les configurations de collecte des métriques. Dans cet exemple, il y a un seul job nommé
nodequi interroge l’adresseip_machine_hôte:9100pour collecter des données. Cette IP est celle du node exporteur (cf paragraphe suivant). Comme Prometheus est exécuté dans un conteneur Docker utiliserlocalhostdans la configuration de Prometheus ne fonctionnera pas. Il faut spécifier l’adresse IP de la machine où Node Exporter est réellement en cours d’exécution. Pour récupérer cette ip :
ip addr showAinsi, cette configuration permet à Prometheus de collecter des métriques toutes les 5 secondes depuis une cible spécifique et d’évaluer les règles (s’il y en avait) toutes les 5 secondes également. Les étiquettes externes sont appliquées à toutes les séries et alertes pour identifier la source des données.
Pas besoin de mettre nos conteneurs sur le réseau host de docker, bridge suffit. En effet par défaut, Docker crée un réseau bridge dans lequel les conteneurs connectés peuvent accéder à l’adresse IP de l’hôte via l’adresse IP assignée à l’hôte sur le réseau local.
2 - Node Exporter
Un Node Exporter est un composant essentiel dans l’écosystème Prometheus. Son rôle principal est de collecter et d’exposer des métriques concernant l’état du système d’exploitation et de la machine hôte sur laquelle il est déployé.
Nous allons donc télécharger le node exporter sur notre machine hôte :
wget/curl -o https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
# remarque : ici soit wget, soit curl -o
# Télécharge l'archive du Node Exporter version 0.18.1 pour Linux (architecture amd64) depuis le dépôt GitHub de Prometheus.
sudo tar -xzvf node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/bin
# Décompresse l'archive téléchargée dans le répertoire '/usr/local/bin'.
# L'option '-x' extrait les fichiers, '-z' gère la compression gzip, '-v' affiche les fichiers extraits, et '-f' spécifie l'archive à décompresser.
cd /usr/local/bin/node_exporter-0.18.1.linux-amd64/
./node-exporter
# Lance le Node Exporter en exécutant le binaire décompressé à l'étape précédente.
# Cela démarre le service qui commence à collecter et exposer les métriques système.Le terminal devrait alors ressembler à ça :
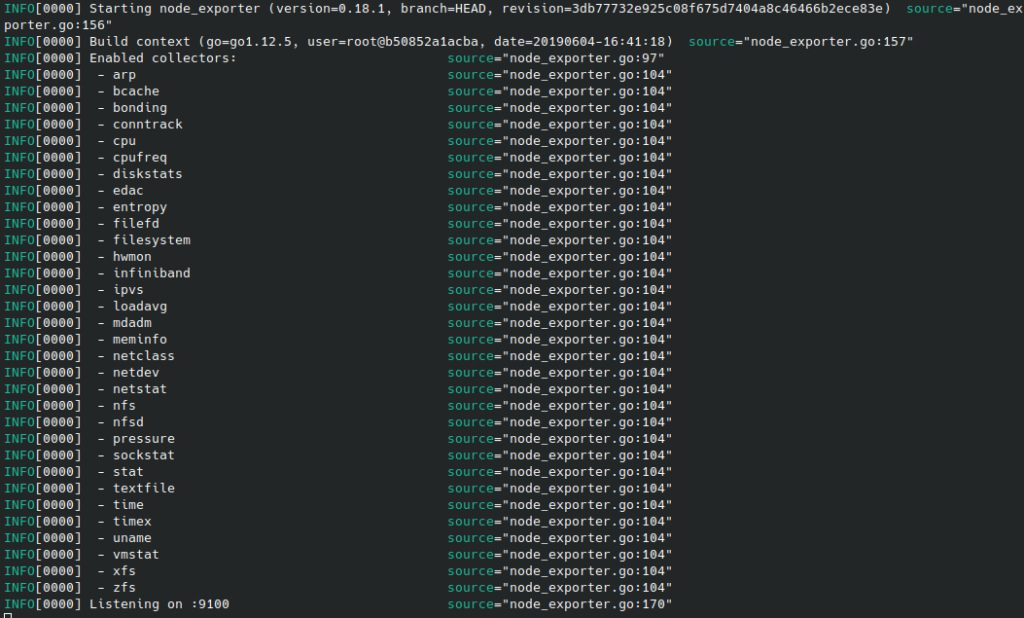
On expose bien les données récoltées sur localhost:9100 (ou ip_machine_hote:9100).
Remarque : pour arrêter le node exporter soit on fait un ctrl + C, soit :
pgrep node_exporter
# renvoi un PID
kill -9 <PID_du_processus>3 - Docker-Compose
On reprend le docker-compose.yaml du precédent article on y ajoute nos conteneurs prometheus et grafana. Le docker-compose complet, en suivant le projet précédent, devrait ressembler à cela :
version: '3.7'
services:
spark-master:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.master.Master"
ports:
- "9090:8080"
- "7077:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./ScriptsPy:/opt/bitnami/spark/ScriptsPy
- ./models:/opt/bitnami/spark/models
spark-worker-1:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./models:/opt/bitnami/spark/models
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077
spark-worker-2:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./models:/opt/bitnami/spark/models
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077
prometheus:
image: prom/prometheus
container_name: prometheus
ports:
- "9091:9090"
volumes:
- ./etc/prometheus:/etc/prometheus
- ./data/prometheus:/prometheus/
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
grafana:
user: root
image: grafana/grafana
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- ./data/grafana:/var/lib/grafana
- ./etc/grafana/:/etc/grafana/provisioning
depends_on:
- prometheus
On lance le tout :
docker compose up -d4 - Prometheus et Grafana
Prometheus
Sur notre localhost:9091 dans le menu Status>Target on retrouve bien notre node exporteur qui renvoie les fameuses « metrics » :

Grafana
Sur notre localhost:3000 on se connecte à Grafana avec:
- user: admin
- mdp: admin
On est alors invités à changer de mot de passe. On peut cliquer sur Skip pour passer directement à l’IHM de Grafana.
Dashboard > + Create Dashboard
+ Add Visualization
Configure a New Data Source > Prometheus
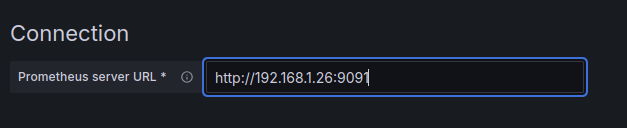
On met l’adresse de notre conteneur puis Save & test
Rappel : on remplace localhost par la réelle ip de la machine hôte
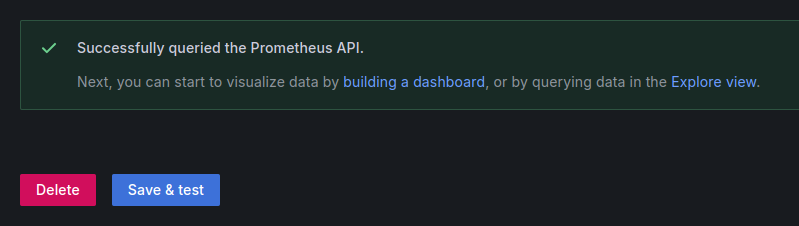
On clique sur building a dashboard et c’est parti ! Il n’ a plus qu’a trouver un tuto Grafana pour monitorer tout ça !
Petite vidéo complémentaire !

