
Dockerisation d’un cluster Spark
Lancer un cluster Apache Spark dans des conteneurs Docker permet de comprendre les concepts essentiels du traitement distribué et du Big Data en utilisant Spark, une des technologies les plus prisées dans ce domaine. De plus, l’utilisation de Docker simplifie la création, le déploiement et la gestion de l’environnement de calcul distribué.
Pour rédigé cet article je me suis appuyé sur le suivant : Using Apache Spark Docker containers to run pyspark programs using spark-submit | by Mehmood Amjad | Medium
1 - Spark vs Pandas

Grossièrement PySpark et Pandas sont similaires dans leur approche de la gestion des données avec l’utilisation de dataframes. Quelques différences notables :
- Spark permet d’effectuer facilement du calcul distribué, alors que Pandas ne supporte pas le calcul distribué de manière native. (il existe des bibliothèques qui étendent les capacités de Pandas pour le calcul distribué, voir Dask et Ray)
- Pandas fonctionne avec un écosystème de librairies python telles que NumPy, Scikit-Learn ou Matplotlib. Spark fonctionne avec l’écosystème Apache.
2 - Comment ça marche ?
Le calcul distribué sert à traiter de grandes quantités de données ou à réaliser des calculs complexes plus rapidement en répartissant le travail entre plusieurs serveurs. Au lieu d’utiliser une seule ressource pour effectuer toutes les tâches, le calcul distribué utilise plusieurs machines qui travaillent ensemble en parallèle. Chaque machine traite une partie du travail, ce qui permet de gagner du temps et de gérer des volumes de données trop importants pour un seul ordinateur.
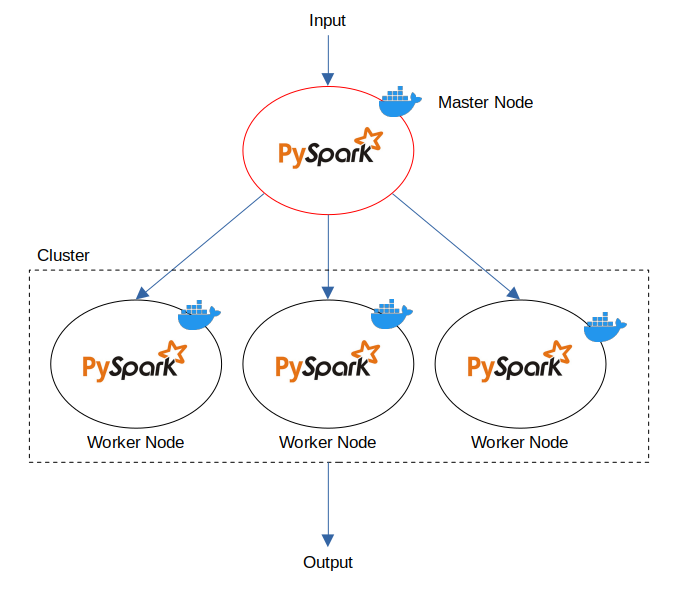
Alors pourquoi utiliser Docker ?
En effet, l’intérêt du calcul distribué est de permettre le scaling horizontal des ressources en mutualisant les puissances de calcul de plusieurs serveurs. Déployer un cluster sur un même PC pourrait sembler inutile, mais Docker permet d’émuler différents serveurs en local et de comprendre le fonctionnement de PySpark. En situation réelle, le nœud maître (master node) et les nœuds esclaves (worker nodes) devront être déployés sur des machines distinctes pour tirer pleinement parti de la technologie.
Les grandes lignes de l’installation
La commande pip install pyspark installe la bibliothèque PySpark qui permet d’interagir avec un cluster Apache Spark existant. Cependant, pour exécuter un cluster Spark avec un nœud maître et des nœuds esclaves, vous devez télécharger et configurer Apache Spark (Le nœud maître et les nœuds travailleurs doivent évidemment être sur le même réseau).
Voici les étapes générales pour déployer un cluster Spark :
- Téléchargez l’archive Spark depuis le site officiel d’Apache Spark : Téléchargement Apache Spark
- Extraire l’archive dans le répertoire de votre choix sur chaque nœud du cluster.
- Configurer le fichier de configuration conf/spark-env.sh pour chaque nœud, en particulier en spécifiant le rôle du nœud (maître ou esclave) et en définissant les propriétés telles que l’URL du maître.
- Utiliser la commande sbin/start-master.sh sur le nœud maître pour démarrer le nœud maître.
- Utiliser la commande sbin/start-worker.sh sur chaque nœud esclave pour démarrer les nœuds esclaves.
- Sur votre machine locale ou tout autre endroit où vous souhaitez soumettre vos tâches Spark, utilisez PySpark pour soumettre des applications Spark au cluster.
Ici nous ne nous attarderons pas plus sur les détails car notre version conteneurisée est bien plus simple.
Comment enregistrer les worker nodes auprès du master node ?
Le nœud maître et les nœuds esclaves communiquent entre eux pour coordonner l’exécution des tâches Spark sur le cluster. Pour cela le nœud maître dans un cluster Spark sait quels nœuds sont enregistrés en tant que nœuds esclaves. Lorsqu’on démarre un nœud esclave (Worker), il se connecte au nœud maître pour s’enregistrer et signaler qu’il est disponible pour exécuter des tâches Spark.
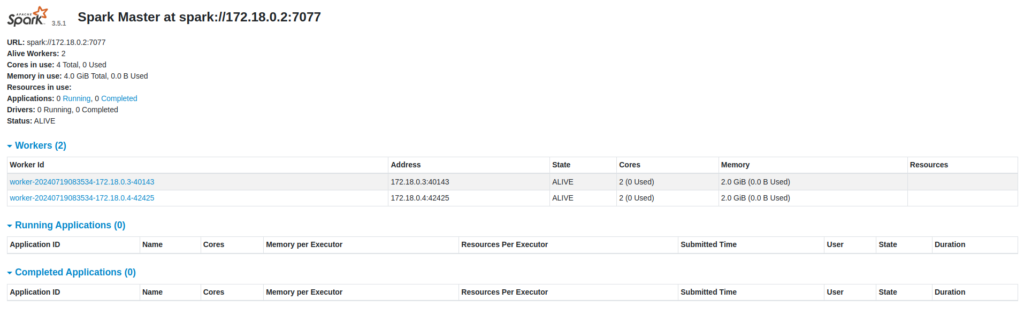
Lorsqu’on démarre le nœud maître, il affiche sur son interface web (par défaut sur le port 8080) la liste des nœuds esclaves qui se sont enregistrés avec lui. Vous pouvez voir cette liste sous la section « Workers » de l’interface web, ainsi que leur état.
La commande :
bin/spark-class org.apache.spark.deploy.worker.Worker spark://<master-url>:7077est utilisée pour démarrer un nœud esclave (Worker) et le faire enregistrer auprès du nœud maître du cluster Spark.
- bin/spark-class: C’est le script qui est utilisé pour exécuter une classe Java spécifiée. Il est utilisé ici pour lancer le nœud esclave Spark.
- org.apache.spark.deploy.worker.Worker: C’est la classe Java qui implémente le nœud esclave dans Spark.
- spark://<master-url>:7077: C’est l’URL du nœud maître. Le nœud esclave utilise cette URL pour s’enregistrer auprès du nœud maître. En exécutant cette commande sur un nœud esclave, vous indiquez au nœud esclave de se connecter au nœud maître spécifié dans l’URL et de s’enregistrer en tant que nœud esclave disponible pour recevoir des tâches Spark.
3 - Cas pratique (Docker)
A - Lancement
Prérequis : Avoir installé Docker.
Dans notre exemple nous souhaitons entraîner un modèle de machine learning avec la librairie sparkML, et enregistrer le modèle entraîné dans le dossier « models ».
Dans le répertoire projet créer une architecture de dossier comme suit :
project-root/
│
├── docker-compose.yml
│
├── data/
│ ├── example_data.csv
│ └── ...
│
├── ScriptsPy/
│ ├── example_script.py
│ └── ...
│
├── models/
├── example_model.pkl
└── ...
Le fichier docker-compose.yml contient les conteneurs suivants :
version: '3.7'
services:
spark-master:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.master.Master"
ports:
- "9090:8080"
- "7077:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./ScriptsPy:/opt/bitnami/spark/ScriptsPy
- ./models:/opt/bitnami/spark/models
spark-worker-1:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./models:/opt/bitnami/spark/models
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077
spark-worker-2:
image: bitnami/spark:latest
command: bash -c "pip install numpy && bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077"
volumes:
- ./data:/opt/bitnami/spark/data
- ./models:/opt/bitnami/spark/models
depends_on:
- spark-master
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077spark-master : Définit le service pour le nœud maître du cluster Spark.
- image: bitnami/spark:latest : Utilise l’image Docker Spark fournie par Bitnami. Pyspark est inclu dans l’image, donc pas besoin de le réinstaller
- command bash -c « pip install numpy && bin/spark-class org.apache.spark.deploy.master.Master » : Exécute une commande bash pour installer numpy et démarrer le nœud maître Spark.
- ports: « 9090:8080 » : Le port 8080 du conteneur (interface Web de Spark) est mappé au port 9090 de l’hôte.
« 7077:7077 » : Le port 7077 du conteneur (port de communication du nœud maître) est mappé au port 7077 de l’hôte. - volumes : Monte des volumes locaux dans le conteneur pour partager les données et les scripts.
spark-worker-1 : Définit le service pour le premier nœud travailleur du cluster Spark.
- image: bitnami/spark:latest : Utilise l’image Docker Spark fournie par Bitnami.
- command: bash -c « pip install numpy && bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077 » : Installe numpy puis lance la classe travailleur de Spark, se connectant au nœud maître spécifié.
- volumes : Monte des volumes locaux dans le conteneur pour partager les données et les modèles.
- depends_on : Spécifie que ce service dépend du service spark-master, assurant que le noeud maître est démarré avant ce travailleur.
- environment : Définit les variables d’environnement pour configurer le nœud travailleur Spark.
- SPARK_MODE: worker : Spécifie que ce nœud doit fonctionner en mode travailleur.
- SPARK_WORKER_CORES: 2 : Attribue 2 cœurs CPU au nœud travailleur.
- SPARK_WORKER_MEMORY: 2g : Attribue 2 Go de mémoire au nœud travailleur.
- SPARK_MASTER_URL: spark://spark-master:7077 : URL du nœud maître auquel ce nœud travailleur doit se connecter.
docker compose up --buildLe cluster est lancé !
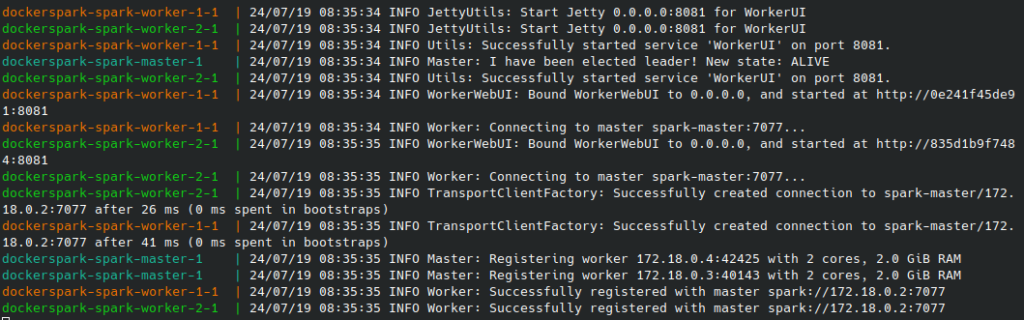
B - IHM du master node
Pour avoir accès à l’UI du master node il suffit d’aller sur localhost:9090 :
C - Lancement d'un Script PySpark
Commençons simplement pour comprendre le fonctionnement.
Dans le dossier ScriptsPy creer un fichier your_program.py tel que :
# Import the necessary modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# Démarre la construction d'une session Spark
#Spécifie le nom de l'application Spark. Ici, elle est nommée "My App".
spark = SparkSession.builder \
.appName("My App") \
.getOrCreate() #Obtient une session Spark existante ou en crée une nouvelle si elle n'existe pas déjà.
## Création d'un RDD contenant les nombres de 1 à 99
rdd = spark.sparkContext.parallelize(range(1, 100))
# spark.sparkContext fait référence au contexte Spark,
# et parallelize distribue la liste entre les nœuds du cluster Spark pour le traitement parallèle.
# Calcule la somme de tous les éléments du RDD rdd.
#Cette opération est distribuée et exécutée de manière parallèle sur tous les nœuds du cluster Spark.
print("THE SUM IS HERE: ", rdd.sum())
# Arrêter la session Spark proprement pour libérer les ressources du cluster.
spark.stop()| RDD | DataFrame |
|---|---|
|
C’est la structure de données fondamentale dans Spark, représentant une collection immuable et partitionnée d’enregistrements qui peuvent être traités en parallèle : Structure de base pour le traitement parallèle de données brutes et non structurées, nécessitant un contrôle détaillé et des transformations explicites. |
Structure optimisée pour le traitement de données structurées, offrant une interface intuitive pour les opérations SQL, les agrégations, et les jointures, tout en bénéficiant de l’optimisation Catalyst de Spark. |
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <nom-du-conteneur-spark-master>
# Pour avoir le nom du conteneur : docker ps
# Soit ici :
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' dockerspark-spark-master-1
# la commande renvoie dans notre exemple : 172.18.0.2
docker exec -it dockerspark-spark-master-1 shcd ScriptsPy
spark-submit --master spark://<adresse_ip_master>:7077 your_program.py
# par exemple ici :
spark-submit --master spark://172.18.0.2:7077 your_program.py
# remarque : THEORIQUEMENT on pourrait remplacer l'ip par le nom du service :
spark-submit --master spark://spark-master:7077 your_program.py

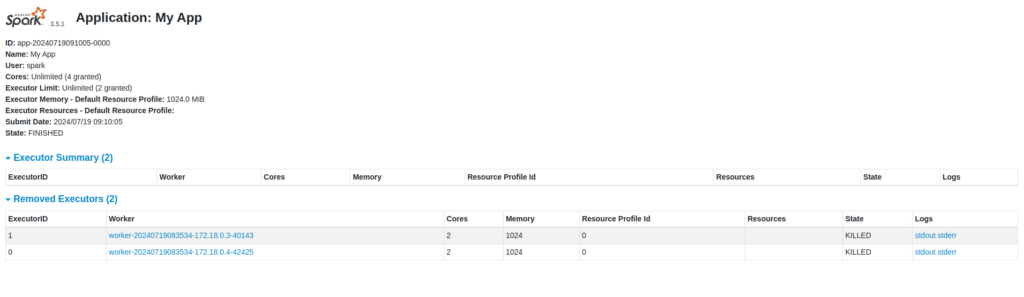
D - Un peu de machine learning avec Spark ML
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
from pyspark.ml.regression import DecisionTreeRegressor
# Créer une session Spark
spark = SparkSession.builder.appName("MyML").getOrCreate()
# Charger le fichier CSV des vols dans un DataFrame Spark
psdf_flights = spark.read.csv(
"file:///opt/bitnami/spark/data/flights.csv", header=True, inferSchema=True
)
# Remplir les valeurs manquantes avec 0
psdf_flights = psdf_flights.fillna(0)
# Utiliser StringIndexer pour numériser les colonnes "ORIGIN_AIRPORT", "DESTINATION_AIRPORT" et "AIRLINE"
indexer_origin = StringIndexer(
inputCol="ORIGIN_AIRPORT", outputCol="ORIGIN_AIRPORT_Index"
)
indexer_destination = StringIndexer(
inputCol="DESTINATION_AIRPORT", outputCol="DESTINATION_AIRPORT_Index"
)
indexer_airline = StringIndexer(inputCol="AIRLINE", outputCol="AIRLINE_Index")
# Créer un pipeline pour appliquer les transformations en une seule étape
pipeline = Pipeline(stages=[indexer_origin, indexer_destination, indexer_airline])
# Appliquer le pipeline de transformation sur les données de vol
psdf_indexe = pipeline.fit(psdf_flights).transform(psdf_flights)
# Utiliser VectorAssembler pour assembler toutes les colonnes de caractéristiques en une seule colonne de vecteur
featureAssembler = VectorAssembler(
inputCols=[
"YEAR", "MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE_Index", "FLIGHT_NUMBER",
"ORIGIN_AIRPORT_Index", "DESTINATION_AIRPORT_Index", "SCHEDULED_DEPARTURE",
"DEPARTURE_TIME", "DEPARTURE_DELAY", "TAXI_OUT", "WHEELS_OFF", "SCHEDULED_TIME",
"ELAPSED_TIME", "AIR_TIME", "DISTANCE", "WHEELS_ON", "TAXI_IN", "SCHEDULED_ARRIVAL",
"ARRIVAL_TIME", "DIVERTED", "CANCELLED", "AIR_SYSTEM_DELAY", "SECURITY_DELAY",
"AIRLINE_DELAY", "LATE_AIRCRAFT_DELAY", "WEATHER_DELAY"
],
outputCol="IndependantFeatures",
) # Cette ligne crée une nouvelle colonne avec les caractéristiques assemblées
# Appliquer la transformation pour assembler les caractéristiques
output = featureAssembler.transform(psdf_indexe)
# Sélectionner les caractéristiques indépendantes et la variable cible (ARRIVAL_DELAY)
spdf_to_ML = output.select("IndependantFeatures", "ARRIVAL_DELAY")
# Diviser les données en ensembles d'entraînement (75%) et de test (25%) avec une graine pour la reproductibilité
train_data_dt, test_data_dt = spdf_to_ML.randomSplit([0.75, 0.25], seed=41)
# Initialiser le régressseur d'arbre de décision
regressor_dt = DecisionTreeRegressor(
featuresCol="IndependantFeatures", labelCol="ARRIVAL_DELAY", maxBins=800
)
# Entraîner le modèle sur les données d'entraînement
model_dt = regressor_dt.fit(train_data_dt)
# Faire des prédictions sur l'ensemble de test
psdf_pred_results_dt = model_dt.transform(test_data_dt)
# Imprimer un message indiquant la fin du traitement
print("FIN DU TRAITEMENT")
# Sauvegarder le modèle entraîné dans le répertoire spécifié
model_dt.write().overwrite().save("/opt/bitnami/spark/models/model_dt")
# Arrêter la session Spark
spark.stop()
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <nom-du-conteneur-spark-master>
# Pour avoir le nom du conteneur : docker ps
# Soit ici :
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' dockerspark-spark-master-1
# la commande renvoie dans notre exemple : 172.18.0.2
# On rentre dans le conteneur
docker exec -it dockerspark-spark-master-1 sh
cd ScriptsPy
spark-submit --master spark://<adresse_ip_master>:7077 ML.py
# par exemple ici :
spark-submit --master spark://172.18.0.2:7077 ML.py
E - Bonus : Utilisation du modèle généré
Utilisation similaire aux précédentes. On crée notre fichier modeluse.py dans ScriptsPy :
from pyspark.sql import SparkSession
from pyspark.ml.regression import DecisionTreeRegressionModel
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml import Pipeline
# Initialiser la session Spark
spark = SparkSession.builder.appName("LoadModel").getOrCreate()
# Charger le modèle sauvegardé
model_dt = DecisionTreeRegressionModel.load("file:///opt/bitnami/spark/models/model_dt")
# Préparer les nouvelles données
new_data = {
"YEAR": 2024,
"MONTH": 7,
"DAY": 19,
"DAY_OF_WEEK": 5,
"AIRLINE": "AA",
"FLIGHT_NUMBER": 1001,
"ORIGIN_AIRPORT": "JFK",
"DESTINATION_AIRPORT": "LAX",
"SCHEDULED_DEPARTURE": 830,
"DEPARTURE_TIME": 845,
"DEPARTURE_DELAY": 15,
"TAXI_OUT": 20,
"WHEELS_OFF": 865,
"SCHEDULED_TIME": 300,
"ELAPSED_TIME": 320,
"AIR_TIME": 280,
"DISTANCE": 2475,
"WHEELS_ON": 1185,
"TAXI_IN": 15,
"SCHEDULED_ARRIVAL": 1130,
"ARRIVAL_TIME": 1200,
"DIVERTED": 0,
"CANCELLED": 0,
"AIR_SYSTEM_DELAY": 0,
"SECURITY_DELAY": 0,
"AIRLINE_DELAY": 0,
"LATE_AIRCRAFT_DELAY": 0,
"WEATHER_DELAY": 0,
}
# Convertir les données en DataFrame
new_data_df = spark.createDataFrame([new_data])
# Indexer les colonnes
indexer_origin = StringIndexer(inputCol="ORIGIN_AIRPORT", outputCol="ORIGIN_AIRPORT_Index")
indexer_destination = StringIndexer(inputCol="DESTINATION_AIRPORT", outputCol="DESTINATION_AIRPORT_Index")
indexer_airline = StringIndexer(inputCol="AIRLINE", outputCol="AIRLINE_Index")
# Appliquer les indexeurs
pipeline = Pipeline(stages=[indexer_origin, indexer_destination, indexer_airline])
new_data_indexed = pipeline.fit(new_data_df).transform(new_data_df)
# Assembler les caractéristiques
featureAssembler = VectorAssembler(
inputCols=[
"YEAR", "MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE_Index", "FLIGHT_NUMBER",
"ORIGIN_AIRPORT_Index", "DESTINATION_AIRPORT_Index", "SCHEDULED_DEPARTURE",
"DEPARTURE_TIME", "DEPARTURE_DELAY", "TAXI_OUT", "WHEELS_OFF", "SCHEDULED_TIME",
"ELAPSED_TIME", "AIR_TIME", "DISTANCE", "WHEELS_ON", "TAXI_IN",
"SCHEDULED_ARRIVAL", "ARRIVAL_TIME", "DIVERTED", "CANCELLED",
"AIR_SYSTEM_DELAY", "SECURITY_DELAY", "AIRLINE_DELAY", "LATE_AIRCRAFT_DELAY",
"WEATHER_DELAY"
],
outputCol="IndependantFeatures"
)
new_data_features = featureAssembler.transform(new_data_indexed)
# Sélectionner les colonnes de caractéristiques indépendantes
new_data_to_predict = new_data_features.select("IndependantFeatures")
# Faire la prédiction
prediction = model_dt.transform(new_data_to_predict)
# Afficher le résultat
prediction.select("prediction").show()
# Arrêter la session Spark
spark.stop()
Puis dans le conteneur :
# cd ScriptsPy
spark-submit --master spark://172.18.0.2:7077 modeluse.py
BINGO :



