
Rapide Audit de Code
J’entends par la un audit de qualité / sécurité rapide et efficace.
Ici nous prendrons l’exemple d’une application développée en python – Django.
Bien évidemment les résultats des scans qui suivent doivent être analysés pour en tirer les bonnes conclusions.
Securité
Safety
Commençons par un scan des librairies utilisées afin d’analyser les éventuelles vulnérabilités.
Safety est idéal pour ça : ce scan utilise une BDD en ligne pour regarder les vulnérabilités dans les packages utilisés par l’application. La BDD en question est mise à jour tous les mois.
Dans un invite de commandes se placer dans le répertoire à scanner :
#Installation
pip install safety
#création du rapport
safety check --file requirements.txt --html > report-safety.htmlIci on scan les dépendances répertoriées dans le fichier requirements.txt pour générer un rapport au format HTML nommé report.html.
Safety check sans argument va analyser les librairies / dépendance de l’environnement python en entier et faire un rapport dans le terminal.
OWASP ZAP

L’utilisation de OWASP ZAP sera détaillée dans un article distinct, mais brièvement, OWASP ZAP (Zed Attack Proxy) est un outil open source largement utilisé dans les audits de sécurité des applications web. En tant que proxy intermédiaire, ZAP permet aux auditeurs de code de scanner les applications web pour détecter et corriger les vulnérabilités de sécurité telles que les injections SQL, les attaques de type Cross-Site Scripting (XSS), les failles de sécurité de session, et bien d’autres encore. En simulant des attaques automatisées et en analysant les réponses de l’application, ZAP peut identifier les points faibles potentiels et fournir des recommandations pour les corriger, aidant ainsi à renforcer la sécurité des applications web.
En attendant quelques liens utiles :
Bandit

L’utilisation de la librairie Bandit de Python peut être considérée comme un complément à SonarQube, axé spécifiquement sur la sécurité du code Python.
Bandit se concentre principalement sur l’identification des vulnérabilités de sécurité dans le code Python, tandis que SonarQube offre une analyse plus large, couvrant divers aspects de la qualité du code, y compris la sécurité, mais sur plusieurs langages de programmation (nous y reviendrons).
Bandit génère un rapport avec des informations sur les vulnérabilités potentielles trouvées dans le code. Il attribue des niveaux de gravité aux différentes vulnérabilités ce qui permet de prioriser les corrections.
#installation
pip install bandit
#analyse récursive de tous les fichiers du répertoire courant
bandit -r . --format html -o /path/rapport-bandit.html --exclude **/__pycache__/**Cette commande exécutera une analyse de sécurité statique sur le code Python dans le répertoire courant (-r .) et ses sous-répertoires en utilisant Bandit. Le rapport de l’analyse sera ensuite formaté en HTML et enregistré dans le chemin spécifié (-o ou --output), en excluant les fichiers se trouvant dans des répertoires __pycache__.

L’utilisation de sonarqube est assez intuitive et nous ne nous attarderons pas ici sur l’interface graphique ou l’analyse, mais plutôt sur comment déployer rapidement une version conteneurisée et scanner notre application.
# Lancement de Sonarqube dans un conteneur
docker run -d --name sonarqube -p 9000:9000 -p 9092:9092 sonarqubeSe rendre sur localhost:9000 et se laisser guider par l’interface graphique.
Pour l’exemple :
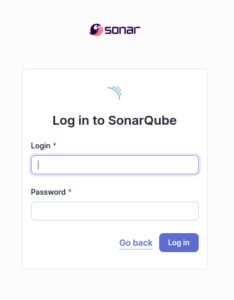 login : admin
login : admin
mdp : admin
(le mot de passe sera demandé à être changé à l’étape d’après)
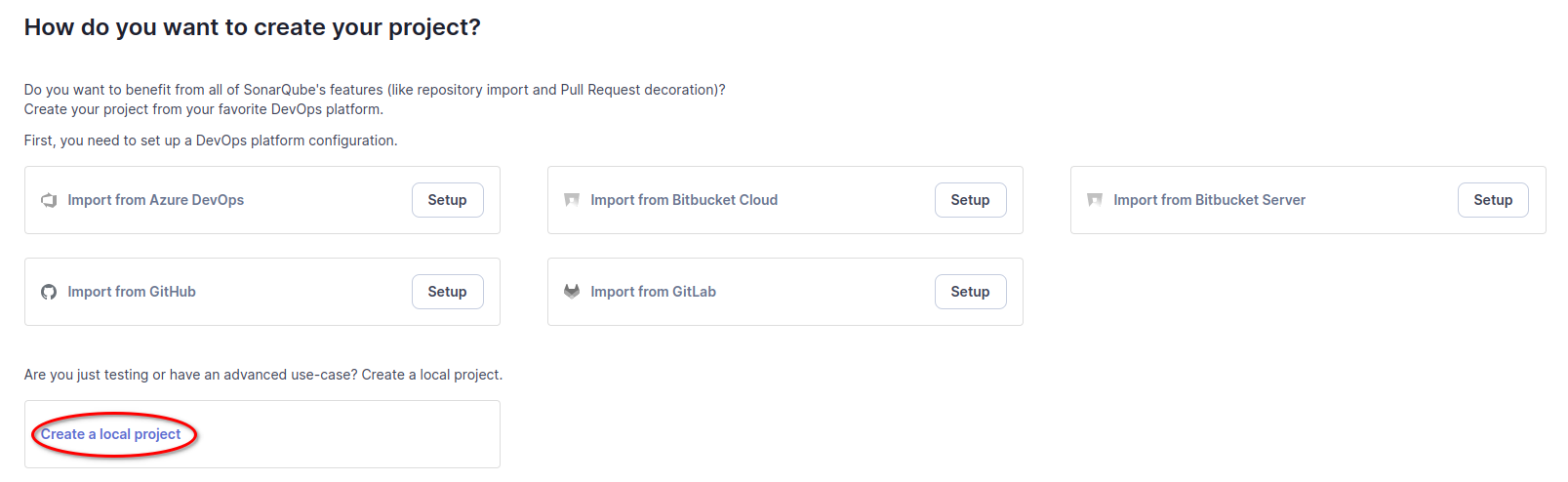
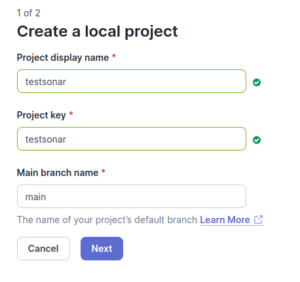
La clé de projet (projectKey sera importante pour la suite !)
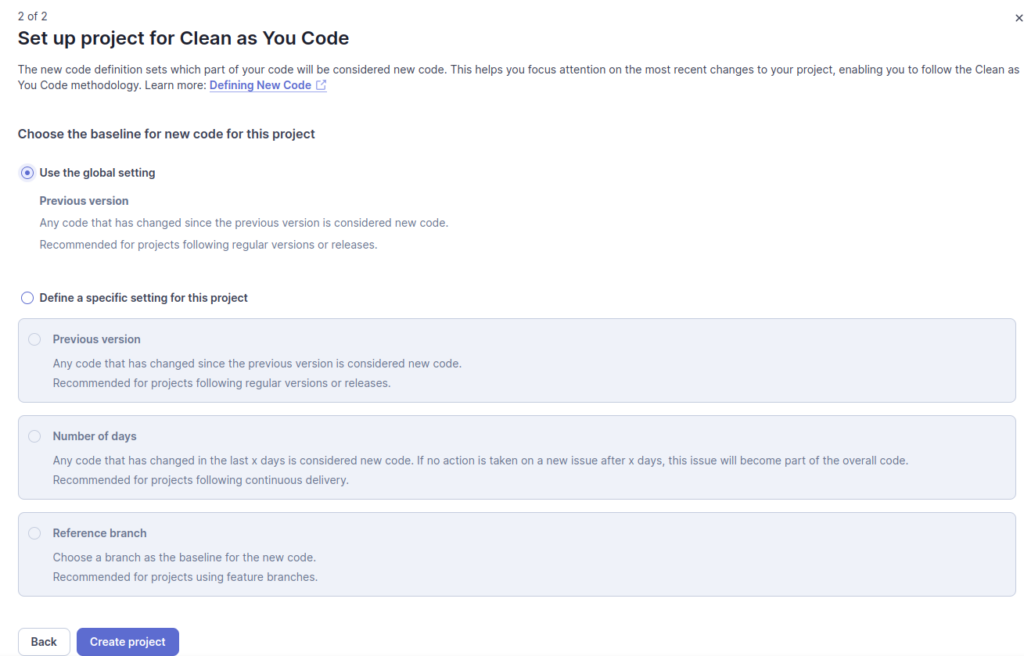
Trivial pour notre exemple
Ici on génère un token qui nous servira à passe le scan :
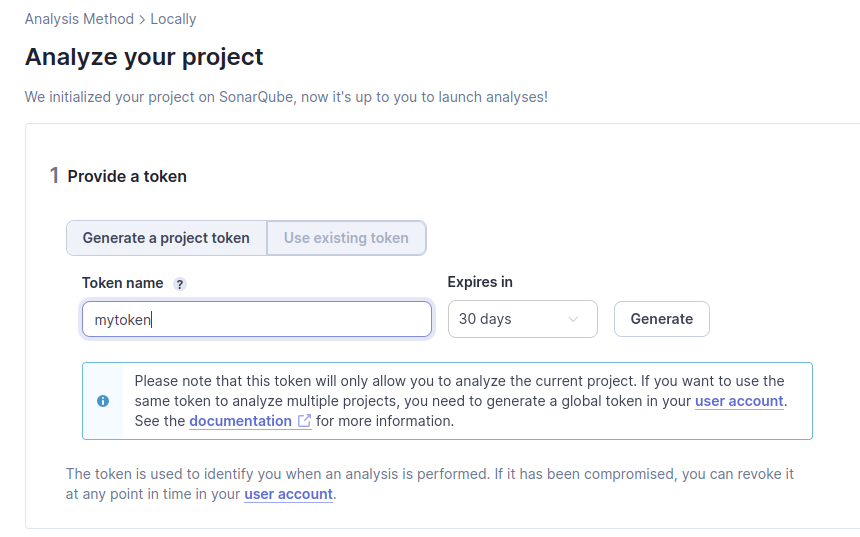
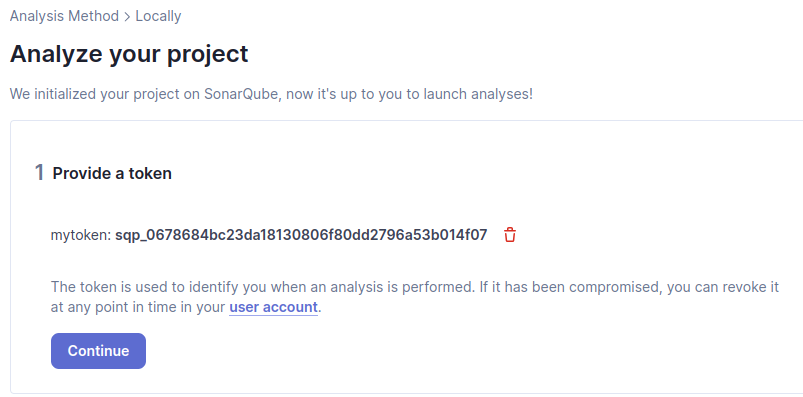
Pour l’exemple : Python – Linux
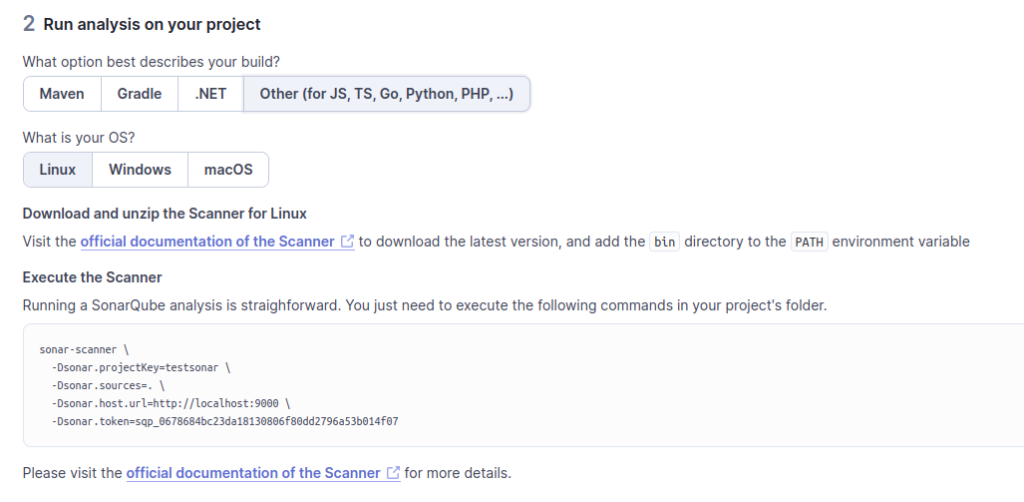
Et ici ATTENTION au piège
Attention, ici la ligne de commande proposée ne fonctionnera pas car nous sommes sur une version conteneurisée. Globalement il faut suivre les instructions de la documentation officielle . L’idée est de lancer un conteneur avec l’image sonar-scanner-cli qui enverra le resultat du scan automatiquement dans l’ihm de notre localhost:9000.
#Dans le repertoire de l'application à scanner
docker run \
--rm \
-e SONAR_HOST_URL="http://${SONARQUBE_URL}" \
-v "${YOUR_REPO}:/usr/src" \
sonarsource/sonar-scanner-cli
# Soit ici pour l'exemple :
docker run --rm -e SONAR_HOST_URL="http://172.17.0.2:9000" -e SONAR_TOKEN="sqp_0678684bc23da18130806f80dd2796a53b014f07" -v "${PWD}:/usr/src" sonarsource/sonar-scanner-cli -X -Dsonar.projectKey=testsonar -Dsonar.sources=. -Dsonar.exclusions=**/*test*.py
- docker run: Comme précédemment, cette commande est utilisée pour exécuter une image Docker dans un nouveau conteneur.
- –rm: C’est une option qui indique à Docker de supprimer automatiquement le conteneur une fois qu’il a terminé son exécution. Cela permet de nettoyer automatiquement les conteneurs temporaires après leur exécution.
- -e SONAR_HOST_URL= »http://172.23.128.1:9000″: Cela définit une variable d’environnement SONAR_HOST_URL dans le conteneur avec l’URL de l’instance SonarQube à laquelle le scanner doit envoyer les résultats de l’analyse. Dans cet exemple, l’URL spécifiée est « http://172.23.128.1:9000 ». Pour obtenir l’ip du conteneur dans lequel tourne notre sonarqube :
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <nom ou ID du conteneur>
# soit ici :
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' sonarqube
-
- -e SONAR_TOKEN= »sqp_0678684bc23da18130806f80dd2796a53b014f07″: Cela définit une autre variable d’environnement SONAR_TOKEN contenant le jeton d’authentification nécessaire pour que le scanner SonarQube puisse envoyer les résultats à l’instance SonarQube.
- –v « ${PWD}:/usr/src »: Cela monte le répertoire de travail actuel (${PWD}) dans le conteneur à l’emplacement /usr/src. Cela permet au scanner SonarQube d’accéder aux fichiers du projet à analyser.
- sonarsource/sonar-scanner-cli: C’est le nom de l’image Docker à partir de laquelle le conteneur est créé. Dans ce cas, il s’agit de l’image Docker officielle contenant le scanner SonarQube CLI.
- -X: Cela active le mode de débogage pour le scanner SonarQube CLI, ce qui affiche des informations de débogage détaillées pendant l’exécution.
- -Dsonar.projectKey=testsonar: Cela définit la clé du projet SonarQube. La clé du projet est utilisée pour identifier de manière unique un projet dans SonarQube. Elle à été définie en amont dans l’IHM (cf capture onglet « projectKey », ou dans l’onglet « project information » de l’IHM).
- -Dsonar.sources=.: Cela spécifie les répertoires sources à analyser. Dans ce cas, le point (.) signifie que le scanner doit analyser le répertoire actuel.
- -Dsonar.exclusions=**/*test*.py: Cela définit les fichiers à exclure de l’analyse. Dans cet exemple, tous les fichiers dont le nom contient « test » et se terminent par « .py » seront exclus de l’analyse.
L’IHM du localhost:9000 se met alors automatiquement à jour. Il n’y a plus qu’a analyser !
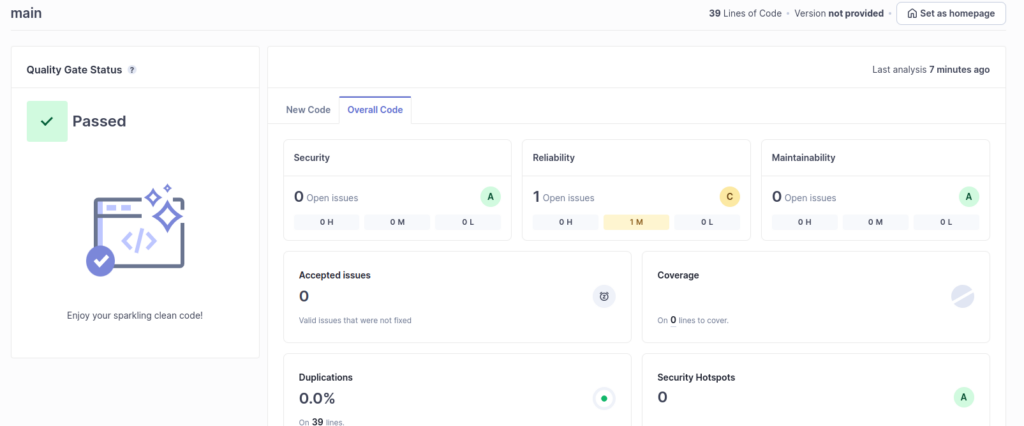
Couverture des tests
Coverage
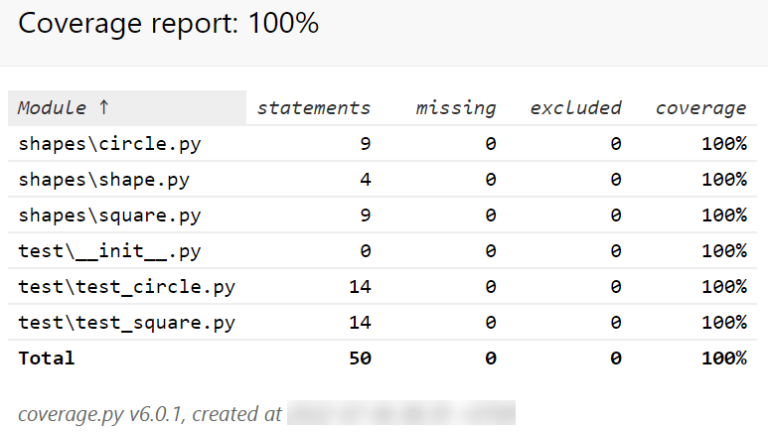
Coverage est un outil de test pour Python utilisé en conjonction avec des tests automatisés pour mesurer le niveau de couverture du code. Il indique le pourcentage de lignes de code exécutées lors des tests, aidant ainsi à identifier les parties du code qui ne sont pas couvertes par les tests.
#installation
pip install coverage
#lancement du scan : coverage run suivi de la commande qui lance les tests
#ici nous prenons l'exemple d'un projet django :
coverage run manage.py test
# un fichier .coverage vient d'être généré
# exploitation de ce fichier pour generer un report
coverage html --skip-empty --omit='*/__pycache__/*','*__init.py__*' -d /path/vers/dossier-du-rapport
- –skip-empty: Cette option spécifie à coverage html de sauter les fichiers qui n’ont pas du tout été exécutés lors des tests. Ces fichiers ne seront pas inclus dans le rapport de couverture.
- –omit=’*/__pycache__/*’,’*__init.py__*’ : Cette option permet de spécifier quels fichiers ou quels motifs de noms de fichiers doivent être omis par l’analyse de couverture. Dans cet exemple, les fichiers situés dans les répertoires __pycache__ et les fichiers __init__.py seront omis de l’analyse de couverture.
- -d /path/vers/dossier-du-rapport : Cette option spécifie le répertoire dans lequel le rapport HTML généré sera enregistré.
Remarque : Coverage offre également la possibilité de générer un rapport directement dans le terminal, permettant une vue rapide et pratique du niveau de couverture sans nécessiter de fichiers de sortie supplémentaires.
# après avoir lancé le scan de génération du .coverage
coverage reportBonnes Pratiques
Il est de bon ton d’ajouter un tableau des bonnes pratiques adaptés au langage / framework utilisé avec une validation ou non de celles ci.
Exemple avec les bonnes pratiques Django :

Organisation du code
- Respect de la structure du projet Django en utilisant des applications modulaire - Utilisation des noms de fichiers et répertoires significatifs - Séparation des configurations pour différents environnements - Absence de code mort
Models (BDD)
- Eviter l'utilisation de champs génériques tels que "charfield" pour stocker des données numériques ou temporelles - Utiliser des modèles abstraits pour éviter le redondance du code
Vues
- Appliquer le principe DRY 'Don't Repeat Yourself) en regroupant le code répétitif dans des fonctions - Utiliser les vues basées sur les classes (Class-Based Views) lorsque cela est approprié - Eviter les requêtes excessives en utilisant select_related ou prefetch_related pour optimiser les requêtes liées
URLs et Routage
- Utiliser les routages explicites avec path() ou repath() au lieu de url() - Utiliser les noms de vues dans les modèles d'url pour faciliter la maintenance
Templates (HTML/Jinja)
- Minimiser la logique métier les templates - Eviter la logique complexe dans les templates (la déplacer dans les vues)
Gestion des Statics et Médias
- Servir les fichiers statiques dans django en mode développement mais utiliser un serveur de fichier statique comme Whitenoise ou un serveur web en production - Utiliser le stockage de médias appropriés comme django-storages pour gérer les fichiers téléchargés
Sécurité
- Utiliser django_contrib_auth pour gérer l’authentification des utilisateurs - Eviter l'injection de code avec mark_safe et utiliser plutôt la syntaxe {% autoescape %} dans les templates - Configurer correctement les paramètres de sécurité dans settings.py
Tests
- Ecrire des tests unitaires et de non régression (TU/TNR) pour assurer la fiabilité de l'application - Utiliser les fixtures ou les factories pour créer des données de test
Optimisation des performances
- Cacher les requêtes fréquentes en utilisant le cache de page ou le cache de fragment
Documentation
- Documenter le code de manière exhaustive - Utiliser des docstrings pour documenter les fonctions et les classes - Utiliser Sphinx ou d'autres outils pour générer une documentation lisible - Utiliser des swaggers



Instructif !